Since November 2019, I'm professor at ESPCI (École Supérieure de Physique et de Chimie Industrielles de la Ville de Paris) and
- my research affiliation is in the Miles project of the LAMSADE (Laboratoire d'Analyse et de Modélisation de Systèmes pour l’Aide à la Décision) in Paris-Dauphine University and PSL (Paris Sciences & Lettres).
- Head of the DATA program of PSL.
- Co-head of the Data Science group of the LAMSADE with Joyce El Haddad.
News
- Best paper award at EACL 2024, for "LOCOST: State-Space Models for Long Document Abstractive Summarization". Congratulations to the first authors Florian Le Bronnec and Song Duong for their very nice work !
- Research positions: For September 2024, two postions on Frugality in machine learning and speech processing
- 2 PhD positions
- 1 postdoc position
- Thanks to Sergio Chibbaro for the invitation and organization of this wonderful Workshop at Les Houches.
- Our paper on Lipschitz-Variance-Margin Tradeoff for Enhanced Randomized Smoothing is accepted at ICLR 2024 !!
- LeBenchmark 2.0 is available: more data, two additional tasks. Check the preprint.
- Our paper "Efficient Bound of Lipschitz Constant for Convolutional Layers by Gram Iteration" is at ICML 2023 ! Congratulations to my colleagues: Blaise Delattre, Quentin Barthélemy and Alexandre Araujo.
- Our paper on Curriculum learning for data-driven modeling of dynamical systems is now published in the European Physical Journal.
- With Alex Araujo, Aaron Havens, Blaise Delattre, and Bin Hu, we have a paper accepted at ICLR 2023 (in the top 25%): A Unified Algebraic Perspective on Lipschitz Neural Networks
- A very nice web-page on Relational Data Embeddings by Alexis Cvetkov.
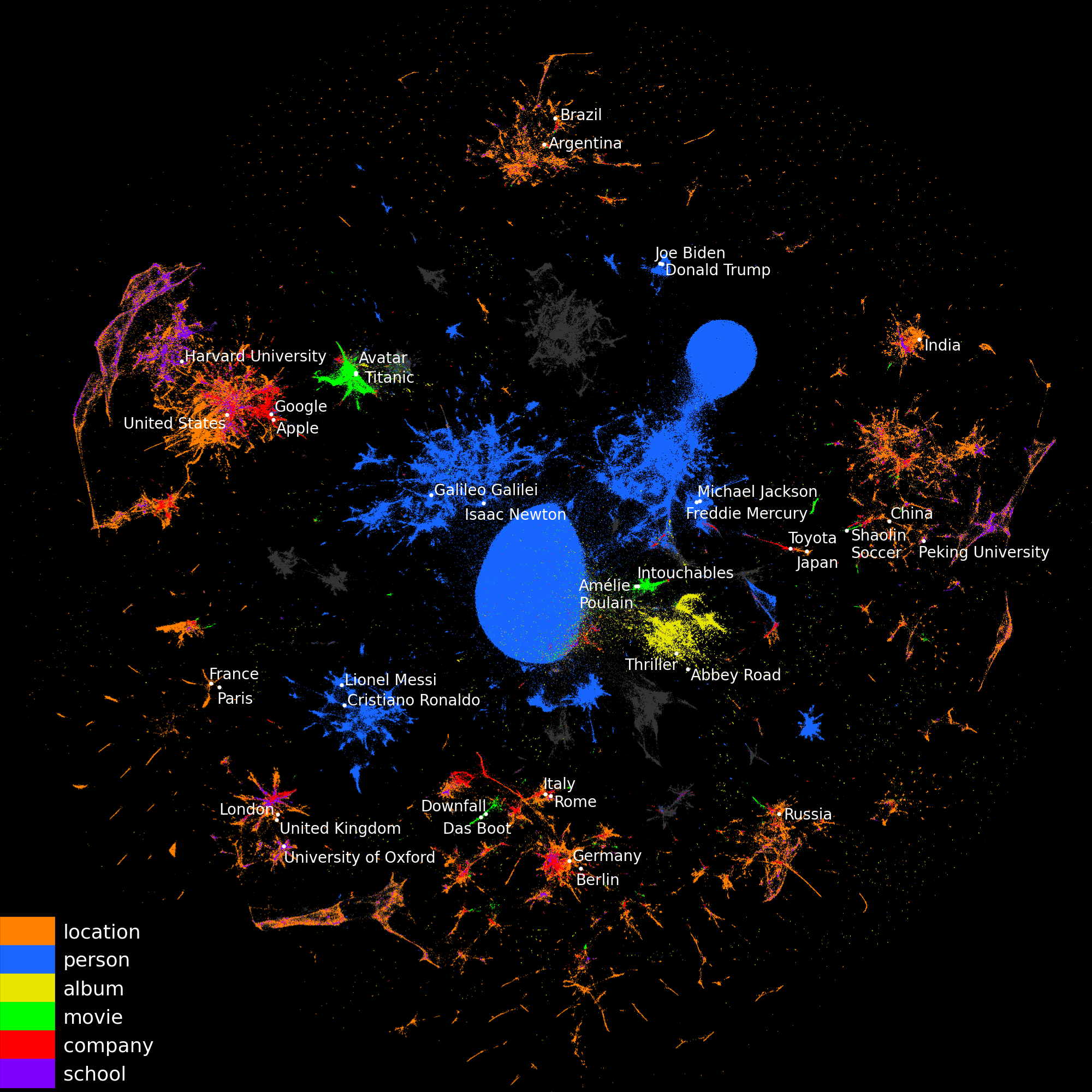
- With Alexis Cvetkov and Gaël Varoquaux from the DirtyData team, we have a paper on Analytics on Non-Normalized Data Sources: More Learning, Rather Than More Cleaning.

- The E-SSL ANR Project is accepted and will start soon. E-SSL stands for "Efficient Self-Supervised Learning for Inclusive and Innovative Speech Technologies". Bravo to Titouan Parcollet, the LIA and the LIG ! A funded PhD position on "Fair and Inclusive Self-Supervised Learning for Speech" will be co-supervised between Paris (LAMSADE) and Grenoble (LIG).
- With Laurent Meunier, Blaise Delattre et Alex Araujo, we have a paper at ICML 2022: A Dynamical System Perspective for Lipschitz Neural Networks.
- with the incredible team of LeBenchmark (from Grenoble and Avignon), we have a paper at NeurIPS 2021 in the datasets and benchmarks track ! Visit our repos.
Table of Contents
Publication
Main research interest
Professor at ESPCI and Researcher in MILES Team of the LAMSADE, my research topics are Natural Language Processing and Deep learning for physical data
Older news
- With Syrielle Montariol, we have a paper at ACL 2021: Measure and Evaluation of Semantic Divergence across Two Languages. The camera ready version will be soon available.
- The summer school ETAL (from the GDR TAL of CNRS) will take place in Lannion (14 to 18 of June 2021). I'm very happy to teach two courses. Check out the program.
- LeBenchmark is out: A Reproducible Framework for Assessing Self-Supervised Representation Learning from Speech. Comming soon at Interspeech 2021.
- FlauBERT and Flue are now available: check the github repository or read our paper on arxiv.
- FLauBERT is a a French BERT trained on a very large and heterogeneous French corpus
- Flue is an evaluation setup for French NLP systems similar to the popular GLUE benchmark
- Read our paper on Control of chaotic systems by Deep Reinforcement Learning. Comming soon, the journal version accepted in The Royal Society’s physical sciences research journal. The journal page is this one.
- Research positions are available for 2021: 2 PhD positions. Coming soon a postdoc position (closed for PhD)
- With Aina Gari Soler and Marianna Apidianaki, we have a paper at *Sem 19 on Word Usage Similarity Estimation with Sentence Representations and Automatic Substitutes.

- See also, the paper in the Semantic Deep Learning (SemDeep-5) workshop at IJCAI: LIMSI-MULTISEM at the IJCAI SemDeep-5 WiC Challenge: Context Representations for Word Usage Similarity Estimation.
- Syrielle Montariol's paper on Empirigcal Study of Diachronic Word Embeddings for Scarce Data is available.
- The special issue on Deep Learning for NLP of the TAL journal is now online, with 3 nice papers.
- November the 23th, a talk at Horizon Maths 2018 : Intelligence Artificielle, organized by the FSMP.
- With Matthieu Labeau : Learning with Noise-Contrastive Estimation: Easing training by learning to scale, in COLING 2018. The paper was one of the "Area Chair Favorites". Meet Matthieu in Santa-Fe.
- Invited Talk at the day "NLP and AI" of the French conference on AI (PFIA) in Nancy (06/07/2018). My talk was about Language models: large vocabulary challenges.
- With Hinrich Schütze and Sophie Rosset, we are editors of a Special issue on Deep-Learning for NLP of the TAL journal. Submit a paper ! See the official page for more detail.
- Our paper Document Neural Autoregressive Distribution Estimation with Stanislas Lauly, Yin Zheng and Hugo Larochelle has been published in JMLR.
- With Matthieu Labeau: Best paper award at SCLeM 2017 with our paper Character and Subword-Based Word Representation for Neural Language Modeling Prediction. If you attend EMNLP workshops, see the talk and the poster, September 7, 2017 in Copenhagen.
- Opening talk at the DGA/IRISA seminar on Artificial Intelligence and Security, 25/04/17. The slides are available here.
- Our paper in Machine translation Journal on A comparison of discriminative training criteria for continuous space translation models is now online
- Matthieu Labeau presents in EACL our paper : An experimental analysis of Noise-Contrastive Estimation: the noise distribution matters
- Invited talk at the Workshop "Statistics/Learning at Paris-Saclay”, Institut des hautes études scientifiques (IHES), 19/01/2017. The slides are available here.
- Our (French) paper in the journal TAL is now online: Apprentissage discriminant de modèles neuronaux pour la traduction automatique. You can check the whole issue which contains other great papers.
- The special issue on Deep Learning for Machine Translation in the journal Computer Speech and Language should be online soon.
- LIMSI Papers at the conference on statistical machine translation, aka WMT17.
- Check the website of the Digicosme working group on Deep Nets and learning representation (in French).
- 3 papers at the first conference on statistical machine translation, aka WMT16.
- Tutorial on Deep learning and NLP applications at the Workshop on Learning with Structured Data and applications on Natural Language and Biology: the slides are available in pdf (the file file is quite large, about 9MB).
- Two Papers at EMNLP this fall 2015
- Three Papers at WMT (see this website), including one with Jan Niehues on ListNet-based MT Rescoring.
- Prix Ex-aequo du meilleur article à TALN 2015 Apprentissage discriminant des modèles continus de traduction
- Check the website of the Digicosme working group on
Deep Nets and learning representation (in French). We will have nice invited speakers for
the upcoming sessions:
- April the 8th: Antoine Bordes (Facebook)
- April the 16th: Florence D'Alché-Buc and Romain Brault (Telecom-ParisTech), along with a discussion lead by Aurélien Decelle (LRI) on "Approximate Message Passing with Restricted Boltzmann Machine Priors"
- May the 22nd: Edward Grefenstette (Google-Deepmind)
- June the 18th: Stéphane Mallat (CMAP)
- Think about submiting to the 3rd edition of the workshop on
Continuous Vector Space Models and their Compositionality (CVSC), with a nice set of
Keynote speakers:
- Kyunghyun Cho (Montreal)
- Stephen Clark (Cambridge)
- Yoav Goldberg (Bar Ilan)
- Ray Mooney (Texas)
- Jason Weston (Facebook AI Research)
- December 2014: Two papers at IWSLT, one of them is on Discriminative Adaptation of Continuous Space Translation Models.
- There will be a third edition of our workshop on Continuous Vector Space Models and their Compositionality (CVSC), colocated with ACL 2015 in Beijing.
- October 2014: AMTA paper Combining Techniques from different NN-based Language Models for Machine Translation with Jan Nieheus is now published
- July the 3rd: Two papers in TALN
- June 2014, WMT14: 3 papers !
- June the 3rd, 2014: talk at l'atelier corpus multilingues, JADT 2014 (in French)
- April 27th 2014: Workshop on Continuous Vector Space Models and their Compositionality, this is the second edition.
- March 25th 2014: talk at the joint one day workshop on "Langue, apprentissage automatique et fouille de données" (in French)
- Habilitation à diriger des recherches (see this page to know what does it mean):
Talks on deep-learning for NLP
- Opening talk at the DGA/IRISA seminar on Artificial Intelligence and Security, 25/04/17. The slides are available here.
- Invited talk at the Workshop "Statistics/Learning at Paris-Saclay”, Institut des hautes études scientifiques (IHES), 19/01/2017. The slides are available here.
- Tutorial on Deep learning and NLP applications at the Workshop on Learning with Structured Data and applications on Natural Language and Biology: the slides are available in pdf (the file file is quite large, about 9MB).
Contact
My postmail address (email prefered):
Alexandre Allauzen Université Dauphine - PSL, Laboratoire LAMSADE, Place du Maréchal de Lattre de Tassigny, 75 775 Paris Cedex 16, France.