Introduction to Deep Learning, ESPCI
This course is over now ! and next year (Jan'2023), it will be different.
This course is an introduction to deep-learning approach with lab sessions in pytorch (python module). The goal is to understand the data-driven approach and to be able to efficiently experiment with deep-learning on real data.
News
- The next lab session is the 21st of Feb 2022
- The second homework is available on the drive. It is a notebook. The deadline is the 7th of February
- For the 17/01, the first lab session: 3 notebooks to do in the following order (see the drive to get the files):
- numpy starter (intro to numpy)
- pytorch starter (intro to pytorch)
- fashion mnist (your first NNet on a image classification task)
- The first homework is available on the drive. The deadline is the 10th of january morning, before the course.
- First course: January the 3th. Early in the morning and remote.
The resources / drive
Look at this drive for the slides, the material of lab sessions, homework, …
Expected schedules
It starts in january 2022 (the 3th). The course is scheduled on monday, starting at 8:30 in the morning.
- 3/01, course: introduction, reminder and basics
- 10/01, course on feed-forward neural networks
- Multi-class classification
- The feed-forward architecture and the back-propagation algorithm
- Pytorch
- 17/01, lab session : 3 notebooks to do in the following order (see the drive to get the files):
- intro to numpy
- intro to pytorch
- your first NNet on a image classification task (Fashion MNIST)
- 24/01, course on deep-learning and Image processing processing
- Deep networks
- Drop out
- Convolution 2D for image processing
- 31/01, course on Sequence classification
- End of tricks (init. and normalization)
- Sequence classification with 1D convolution
- Two examples: text classification and DNA/RNA classification
- Few words on the project
- 07/02, lab session
- Image classification
- 2D convolution
- 14/02, course on sequence model
- Sequence processing with recurrent networks
- LSTM and GRU
- 21/02, lab sesion:
- Convolution in 2D
- …
- 21/03, course: Advanced architecture - part 1 / Project
- Case study : NMT
- Tranformers, BERT and so on …
- 28/03, course: Advanced architecture - part 2 / Project
python and Notebooks: how to
We will use python 3, pytorch and notebooks. If you need to work with own computer, there are 2 ways:
- install anaconda 3 on your computer: see this page.
- use colab with a google account (the easiest, nothing todo)
To use files stored on your google drive you can add in your colab notebook:
from google.colab import drive drive.mount('/content/gdrive') # in my drive, I have a directory "Colab Notebooks" # the dataset is uploaded there root_path = 'gdrive/My Drive/Colab Notebooks/'
If you are not familiar with python notebooks, see this page.
Projects
Here, you can find a list of possible projects. Feel free to interact with me. For some of them, just ask me the data, otherwise a link is provided. Of course, you can also propose a project. This section is under construction and maybe some projects will be added as soon as I will have more feedbacks from my colleagues.
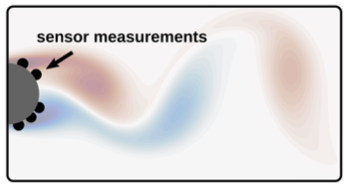
- Reconstruction of the vorticity field of a flow behind a cylinder from a handful sensors on the cylinder surface
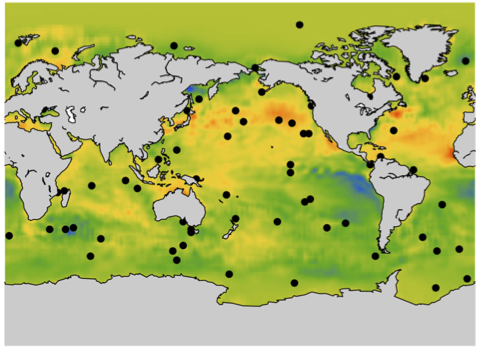
- The mean sea surface temperature reconstruction from weekly sea surface temperatures for the last 26 years. You can also have access to other measures. For this project, you can read the paper associated with the previous project or also look at this recent paper.
- Chaos as an interpretable benchmark for forecasting and data-driven modelling
- Predicting the sequence specificities of DNA- and RNA-binding proteins. We can use datasets from Deep-bind.
- Deep sequence models for protein classification: there is a recent paper on this topic and data can be available. We can try different models (maybe simpler) for the same task.
- Chemistry: Predict the standard density of pure fluids, using a newly compiled database. From SMILES description, how can we predict density ? Ask me for the data and tools.
- Classify sleep and arousal stages from physiological signals including: electroencephalography (EEG), electrooculography (EOG), electromyography (EMG), electrocardiology (EKG), and oxygen saturation (SaO2). See the challenge page for more details
- Classify, from a single short ECG lead recording (between 30 s and 60 s in length), whether the recording shows normal sinus rhythm, atrial fibrillation (AF), an alternative rhythm, or is too noisy to be classified: The challenge page. Other datasets can be nice:
- Using seismic signals to predict the timing of laboratory earthquakes.
- Quantum-mechanical molecular energies prediction from the raw molecular geometry: see the QM7 database.
- Classify Molecule polarization: the data comes from time-lapse fluorescence microscopy images of the bacterium Pseudomonas fluorescens SBW25. Each image is an individual bacterial cell. These bacteria produce a molecule called pyoverdin which is naturally fluorescent, so the images show the distribution of this molecule inside the cells. We have discovered that there are two distribution patterns of this molecule: homogeneous, or accumulated at the cell pole ("polarized").
- Jet Flavor Classification in High-Energy Physics: http://mlphysics.ics.uci.edu/
- Recognize decays in real high energy physics experiment: https://www.kaggle.com/c/beta-beta-decay-identification/data
- A project associated with the course of statistical physics on the XY-model
- Simple Recurrent network for language modelling, coupled with adaptive stepsize
- 1-Lipschitz recurrent networks : language model and DNA sequence analysis